Acceptability rating study
This documentation describes only one part of an experiment. For other tasks, see the related pages.
Acceptability ratings
An acceptability rating or acceptability judgment study is a research method used to understand how people judge the quality or "naturalness" of sentences. Participants are presented with sentences and asked to rate how acceptable or "normal" each sentence sounds, usually on a numerical scale from 1 to 5 or 7. Through these ratings, researchers can learn more about the results of the interpretation processing.
While this demo has a linguistic focus, the template can be used for recording ratings in response to other questions.
Overview
This documentation presents two experiments. One uses the Ibex native AcceptabilityJudgment.js script to show only one prompt and scale (jump to section).
The other uses a combination of PCIbex text and scale scripts to present one or more questions concurrently (jump to section).
The experiments contain an exercise and main experiment section.
The item, condition, list, and item type variables are logged, in addition to the responses and response time.
The structure of the code for both experiments is as follows:
- Setup and Configuration
- Experiment Structure (order of the experiment stages)
- Set Latin square group/select list
- Exercise:
randomize("items-exercise") - Start of main experiment notice:
"start_experiment" - Main experiment:
randomize("items-experiment") - Sending results:
SendResults()
- Stimuli Presentation
- Start of experiment notification
Unlike the self-paced reading study, this study uses simple randomization.
For a fixed order of presentation, remove randomize() from the events sequence and keep only "items-exercise" and "items-experiment".
Dependencies
- Resources
items.csvlist of exercise stimuli
- Scripts
main.js
- Aesthetics
global_main.cssPennController.cssScale.cssQuestion.css(for multiple questions)
- Modules
AcceptabilityJudgment.jsFlashSentence.js(for single question)PennController.jsQuestion.js(for single question)Scale.jsVBox.js(for single question)
Other files, modules and aesthetics may be necessary if your experiment uses other trials, e.g. a form for recording participant information.
Stimulus file
The column names and their capitalization matters. If you change the column names and file name, adjust your code accordingly.
The stimuli are contained in the file items.csv.
The file items.csv has the structure as in the table below.
Those files are equivalent, although the contents of the files differ between the experiments.
You can switch them around if you'd like.
ITEM: the item IDCONDITION: the condition IDTYPE: the stimulus type (exercise,item, orfiller)- exercise: shown only during the exercise trials in random order
- item and filler: shown only during the main experiment trials in pseudorandomized order
SENTENCE: the sentence to be displayed during ratingLIST: the list ID or Latin square group, used for experiment version presentation
| ITEM | CONDITION | TYPE | SENTENCE | LIST |
|---|---|---|---|---|
| 1 | C | item | Niklas war freiwillig zufrieden. | 1 |
| 1 | C | item | Niklas war freiwillig zufrieden. | 1 |
| 1 | A | item | Niklas war absichtlich zufrieden. | 2 |
| 1 | A | item | Niklas war absichtlich zufrieden. | 2 |
| 1 | B | item | Niklas war bewusst zufrieden. | 3 |
| 1001 | filler | filler | Henrike fuhr nach Brasilien. | 1 |
| 1001 | filler | filler | Henrike fuhr nach Brasilien. | 2 |
| 1001 | filler | filler | Henrike fuhr nach Brasilien. | 3 |
| 1001 | filler | filler | Henrike fuhr nach Brasilien. | 1 |
| 1001 | filler | filler | Henrike fuhr nach Brasilien. | 2 |
| 1001 | filler | filler | Henrike fuhr nach Brasilien. | 3 |
| 2001 | exercise | exercise | In Internetforen diskutierten Eltern. | 1 |
| 2001 | exercise | exercise | In Internetforen diskutierten Eltern. | 2 |
| 2001 | exercise | exercise | In Internetforen diskutierten Eltern. | 3 |
Single question
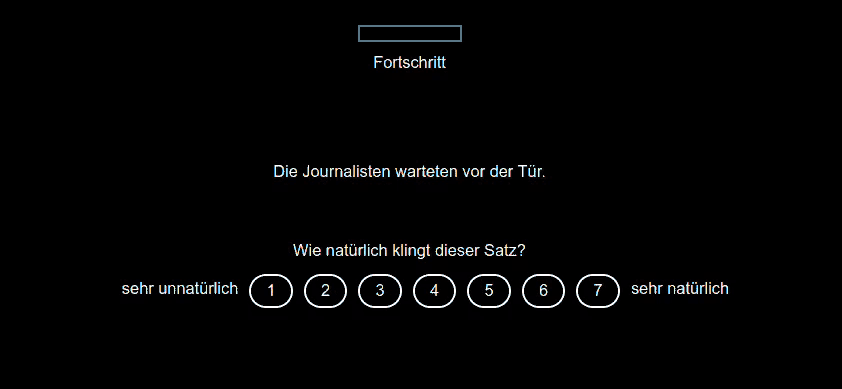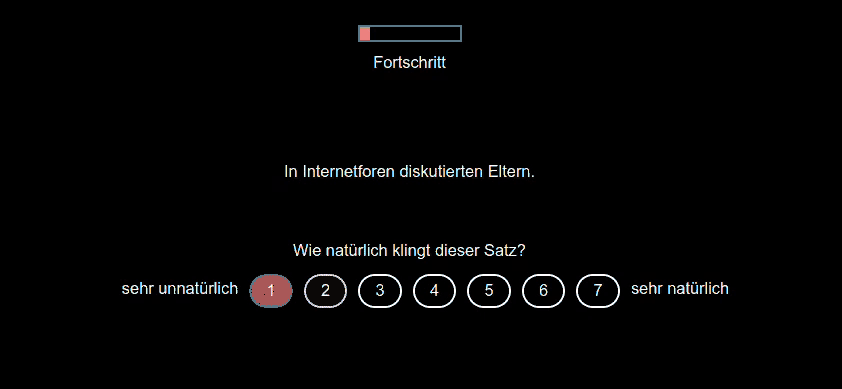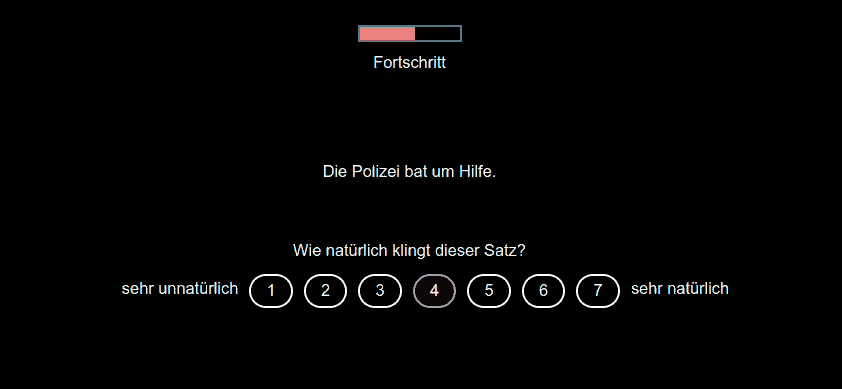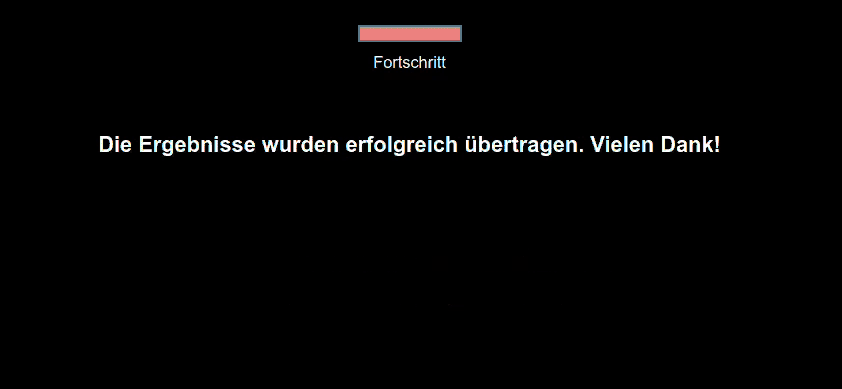
Participants are presented with sentences and are simultaneously asked to rate their naturalness on a 1–7 Likert scale. This implementation ensures randomized presentation of stimuli and result logging for accurate data collection.
Answers can be given by clicking on the number or pressing a predetermined button, e.g. 1-7. When clicking or hovering, the selected option is highlighted, but when pressing a button, the experiment immediately continues.
Acceptability rating with automatic continuation (version 1)
This acceptability rating code is governed by a combination of AcceptabilityJudgment.js,Question.js, Scale.js, and Vbox.js, as well as their corresponding aesthetics.
The AcceptabilityJudgment controller must include the following parameters:
sthe sentenceqthe questionasthe answers
There are other optional parameters, e.g. whether there is a correct answer, which are described in detail in the Ibex documentation.
// Trial
"items.csv", "items-" + row.TYPE,
"AcceptabilityJudgment",
"LIST", row.LIST
"ITEM", row.ITEM
"CONDITION", row.CONDITION
"TYPE", row.TYPE
;
Acceptability rating with automatic continuation (version 2)
If you prefer to display only one question, without the possibility of changing the answer and without having to click on the Continue button, you need to modify the Template() like so:
// Trial
// Acceptability rating trial
"items.csv", "items-"+row.TYPE,
// Display the sentence and the scale
"sentence", row.SENTENCE
,
"question", "Wie natürlich klingt dieser Satz?"
,
"natural", 5
"left", "sehr<br>unnatürlich"
"right", "sehr<br>natürlich"
"1","2","3","4","5"
"top"
,
// Wait briefly to display which option was selected
"wait", 300
// Record trial data
"ITEM" , row.ITEM
"CONDITION", row.SENTENCE
"LIST", row.LIST
;
The key differences from multiple questions are:
- Adding
once()to thenewScale()so that only the first answer is recorded and it cannot be changed. - Adding
newTimer()to briefly show which answer was selected.
Multiple questions

Participants are presented with sentences and are simultaneously asked to rate their naturalness on a 1–5 Likert scale. This implementation ensures randomized presentation of stimuli, validating responses, and result logging for accurate data collection.
Answers can be given by clicking on the number or pressing a predetermined button. Each scale needs its own unique buttons, e.g. 1-5 for scale 1, qwert for scale 2, and asdfg for scale 3. The selected option is highlighted and the experiment continues only if all required questions have been answered.
Multiple questions with manual continuation
This is the default option for this template. The participant must answer three questions before continuing to the next display. They can change the answers.
// Trial
"items.csv", "items-"+row.TYPE,
"sentence", row.SENTENCE
,
"question_1", "Wie natürlich klingt dieser Satz?"
,
"natural", 5
"left", "sehr<br>unnatürlich"
"right", "sehr<br>natürlich"
"1","2","3","4","5"
"top"
,
"question_2", "Wie verständlich ist dieser Satz?"
,
"comprehensible", 5
"left", "sehr<br>unverständlich"
"right", "sehr<br>verständlich"
"q","w","e","r","t"
"top"
,
"question_3", "Wie stilistisch wohlgeformt ist dieser Satz?"
,
"style", 5
"left", "stilistisch<br>sehr schlecht"
"right", "stilistisch<br>sehr gut"
"a","s","d","f","g"
"top"
,
// Clear error messages if the participant changes the input
"check answers", ""
"errorSelect"
,
// Continue only if all the scales have an input
"next_trial", "Weiter"
'dummy',true.testtrue
"natural".test
"comprehensible".test
"style".test
'errorSelect', "Bitte beantworten Sie alle Fragen."
"Crimson"
// Record trial data
"ITEM" , row.ITEM
"CONDITION", row.SENTENCE
"LIST", row.LIST
;
Other code
The following code customizes the progress bar text progressBarText, the automatic sending results message sendingResultsMessage (automatic message displayed when data is being sent), and the completion message completionMessage (automatic message displayed upon successful data transmission). In the absence of an ending display, the completion message is the last thing participants see in an experiment.
It also sets up the counter, which ensures that a new list is started for the next participant.
// Customized messages and counter
;
;
;
"setcounter"
The following code sets up the beginning of an experiment by initializing a new trial and displaying a message to the participants that indicates the experiment is starting. The participants must click on the button Continue to proceed to the next part of the experiment. It's equivallent between both templates.
// Experiment start display
"start_experiment" ,
"<h2>Jetzt beginnt der Hauptteil der Studie.</h2>"
,
"go_to_experiment", "Experiment starten"
Running the code
To run the experiment, clone or download the repository from GitHub. repository containing the experiment files or download them directly. Alternatively, use the demo links provided in the repository to test the experiment online before deploying it:
Once uploaded, launch the experiment through PCIbex to start collecting data.
Old acceptability rating template
An online questionnaire experiment. Participants read a sentence and are simultaneously presented with a 7-point Likert scale. They must to rate how natural the sentence sounds to them before proceeding to the next sentence. This template is no longer maintained.